-
Real MySQL 8.0 6 - 데이터 타입책책책 책을 읽읍시다/프로그래밍 2023. 5. 5. 00:52
문자열(CHAR와 VARCHAR)
저장 공간
우선 CHAR와 VARCHAR의 공통점은 문자열을 저장할 수 있는 데이터 타입이라는 점이고, 가장 큰 차이는 고정 길이냐 가변 길이냐다.
- 고정 길이는 실제 입력되는 컬럼값의 길이에 따라 사용하는 저장 공간의 크기가 변하지 않는다. CHAR 타입은 이미 저장 공간의 크기가 고정적이다. 실제 저장된 값의 유효 크기가 얼마인지 별도로 저장할 필요가 없으므로 추가로 공간이 필요하지 않다.
- 가변 길이는 최대로 저장할 수 있는 값의 길이는 제한돼 있지만, 그 이하 크기의 값이 저장되면 그만큼 저장 공간이 줄어든다. 하지만 VARCHAR 타입은 저장된 값의 유효 크기가 얼마인지를 별도로 저장해 둬야 하므로 1~2바이트의 저장 공간이 추가로 더 필요하다.
하나의 글자를 저장하기 위해 CHAR(1)과 VARCHAR(1) 타입을 사용할 때 실제 사용되는 저장 공간의 크기를 한번 살펴보자. 우선 두 문자열 타입 모두 한 글자를 저장할 때 사용하는 문자 집합에 따라 실제 저장 공간을 1~4바이트까지 사용한다. 여기서 하나의 글자가 CHAR 타입에 저장될 때는 추가 공간이 더 필요하지 않지만 VARCHAR 타입에 저장할 때는 문자열의 길이를 관리하기 위한 1~2 바이트 공간을 추가로 더 사용한다. VARCHAR 타입의 길이가 255바이트 이하이면 1바이트만 사용하고, 256바이트 이상으로 설정되면 2바이트를 사용한다. VARCHAR 타입의 최대 길이는 2바이트로 표현할 수 있는 이상은 사용할 수 없다. 즉, VARCHAR 타입의 최대 길이는 65,536(2의 16승, 2바이트 = 16비트)바이트 이상으로 설정할 수 없다.
MySQL에서는 하나의 레코드에서 TEXT와 BLOB를 제외한 컬럼의 전체 크기가 64KB를 초과할 수 없다. 테이블에 VARCHAR 타입의 컬럼 하나만 있다면 이 VARCHAR 타입은 최대 64KB 크기의 데이터를 저장할 수 있다. 하지만 이미 다른 컬럼에서 40KB의 크기를 사용하고 있다면 VARCHAR 타입은 24KB만 사용할 수 있다. 이때 24KB를 초과하는 크기의 VARCHAR 타입을 생성하려고 하면 에러가 발생하거나 자동으로 VARCHAR 타입이 TEXT 타입으로 대체된다. 그래서 컬럼을 새로 추가할 때는 VARCHAR 타입이 TEXT 타입으로 자동으로 변환되지 않았는지 확인해 보는 것이 좋다.
문자열 타입의 저장 공간을 언급할 때는 1문자와 1바이트를 구분해서 사용한다. 1문자는 실제 저장되는 값의 문자 집합에 따라 1~4바이트까지 공간을 사용할 수 있기 때문이다. 위의 VARCHAR 타입의 컬럼 하나만 가지는 테이블의 예에서 VARCHAR 타입은 최대 64KB 크기의 데이터를 저장할 수 있다고 했는데, 이 수치는 바이트 수를 의미하므로 실제 65,536개의 글자를 저장할 수 있다는 것은 아니다. 실제 저장되는 문자가 아시아권의 언어라면 저장 가능한 글자 수는 반으로 줄고, UTF-8 문자를 저장한다면 저장 가능한 글자 수는 1/4로 줄어들 것이다.CHAR 타입과 VARCHAR 타입을 결정할 때 중요한 판단 기준은 다음과 같다.
- 저장되는 문자열의 길이가 대개 비슷한가?
- 컬럼의 값이 자주 변경되는가?
CHAR와 VARCHAR 타입의 선택 기준은 값의 길이도 중요하지만, 해당 컬럼의 값이 얼마나 자주 변경되느냐가 기준이 돼야 한다 컬럼의 값이 얼마나 자주 변경되느냐가 왜 중요한지 그림으로 한번 살펴보자. 우선 다음과 같이 테스트용 테이블이 있고, 그 테이블에 레코드 1건이 저장된다고 가정해보자.
CREATE TABLE tb_test ( fd1 INT NOT NULL, fd2 CHAR(10) NOT NULL, fd3 DATETIME NOT NULL ); INSERT INTO tb_test (fd1, fd2, fd3) VALUES (1, 'ABCD', '2011-06-27 11:02:11');tb_test 테이블에 레코드 1건을 저장하면 내부적으로 디스크에는 그림과 같이 저장될 것이다.
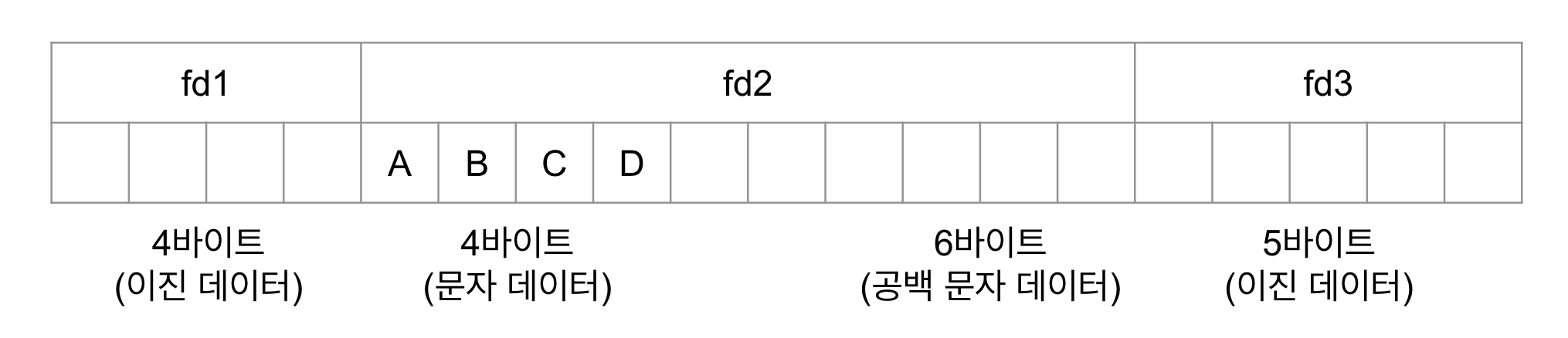
CHAR 타입이 저장된 상태 fd1 컬럼은 INTEGER 타입이므로 고정 길이로 4바이트를 사용하며, fd3 또한 DATETIME이므로 고정 길이로 8바이트를 사용한다. 지금 여기서 관심사는 fd1과 fd3 컬럼이 아니라 그 사이에 위치한 fd2 컬럼이다. fd2 컬럼이 사용하는 공간을 눈여겨보자. 그림에서 fd2 컬럼은 정확히 10바이트를 사용하면서 앞쪽의 4바이트만 유효한 값으로 채워졌고 나머지는 공백 문자로 채워져 있다(그림에서 fd2 컬럼의 빈 공간은 공백 문자(Space character)를 의미한다.).
그러면 이번에는 tb_test 테이블의 fd2 컬러만 CHAR(10) 대신 VARCHAR(10)으로 변경해서 똑같은 데이터를 저장했을 때 디스크에 어떻게 저장되는지 그림으로 살펴보자.
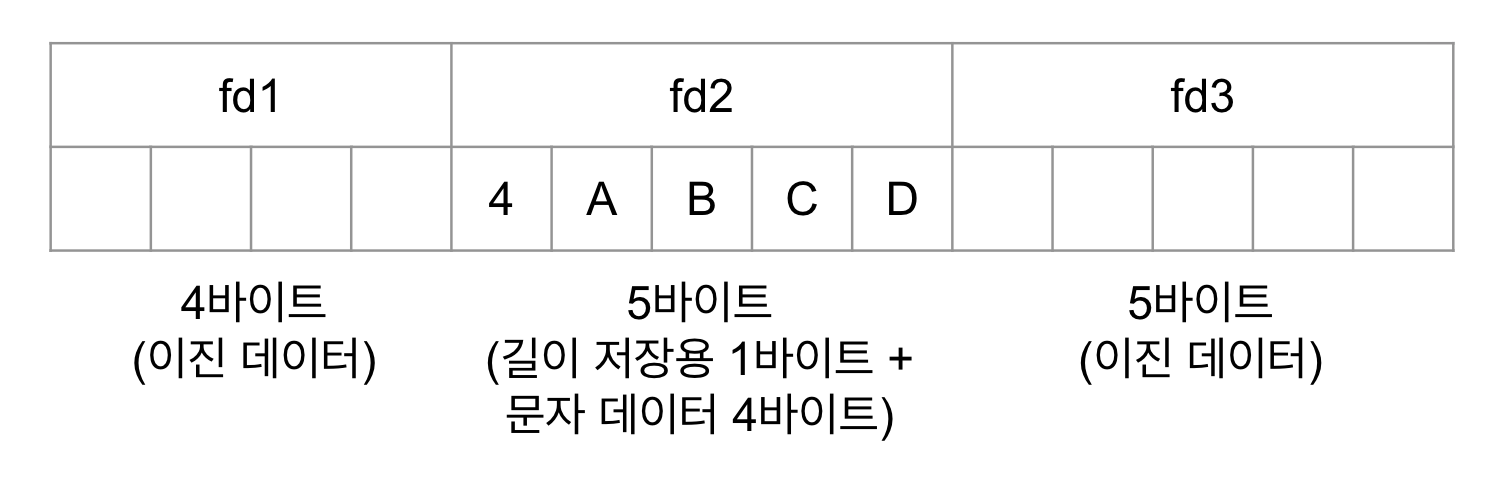
VARCHAR 타입의 컬럼이 저장된 상태 fd1 컬럼과 fd3 컬럼 사이에서 fd2 컬럼은 5바이트의 공간을 차지하는데, 첫 번째 바이트에는 저장된 컬럼값의 유효한 바이트 수인 숫자 4(문자 '4'가 아님)가 저장되고 두 번째 바이트로부터 다섯 번째 바이트까지 실제 컬럼값이 저장된다.
중요한 것은 레코드 한 건이 저장된 상태가 아니라 fd2 컬럼의 값이 변경될 때 어떤 현상이 발생하느냐다. fd2 컬럼의 값을 "ABCDE"로 UPDATE했다고 가정해 보자.
- CHAR(10) 타입을 사용하는 그림에서는 fd2 컬럼을 위해 공간이 10바이트가 준비돼 있으므로 그냥 변경되는 컬럼의 값을 업데이트만 하면 된다.
- VARCHAR(10) 타입을 사용하는 그림에서는 fd2 컬럼에 4바이트 밖에 저장할 수 없는 구조로 만들어져 있다. 그래서 "ABCDE"와 같이 길이가 더 큰 값으로 변경될 때는 레코드 자체를 다른 공간으로 옮겨서(Row migration) 저장해야 한다.
물론 주민등록번호처럼 항상 값의 길이가 고정적일 때는 당연히 CHAR 타입을 사용해야 한다. 또한 값이 2~3바이트씩 차이가 나더라도 자주 변경될 수 있는 부서 번호나 게시물의 상태 값 등은 CHAR 타입을 사용하는 것이 좋다. 자주 변경돼도 레코드가 물리적으로 다른 위치로 이동하거나 분리되지 않아도 되기 때문이다. 레코드의 이동이나 분리는 CHAR 타입으로 인해 발생하는 2~3바이트 공간 낭비보다 더 큰 공간이나 자원을 낭비하게 만든다.
문자열 데이터 타입을 사용할 때 또 하나 주의할 사항이 있다. CHAR나 VARCHAR 키워드 뒤에 인자로 전달하는 숫자 값의 의미를 알아야 한다는 점이다. 다른 DBMS에 익숙한 사용자에게는 상당히 혼란스러울 수 있는데, MySQL에서 CHAR나 VARCHAR 뒤에 지정하는 숫자는 그 컬럼의 바이트 크기가 아니라 문자의 수를 의미한다. 즉, CHAR(10) 또는 VARCHAR(10)으로 컬럼을 정의하면 이 컬럼은 10바이트를 저장할 수 있는 공간이 아니라 10글자(문자)를 저장할 수 있는 공간을 의미한다. 그래서 CHAR(10) 타입을 사용하더라도 이 컬럼이 실제로 디스크나 메모리에서 사용하는 공간은 각각 달라진다.
- 일반적으로 영어를 포함한 서구권 언어는 각 문자가 1바이트를 사용하므로 10바이트를 사용한다.
- 한국어나 일본어와 같은 아시아권 언어는 각 문자가 최대 2바이트를 사용하므로 20바이트를 사용한다.
- UTF-8과 같은 유니코드는 최대 4바이트까지 사용하므로 40바이트까지 사용할 수 있다.
저장 공간과 스키마 변경(Online DDL)
MySQL 서버에서는 데이터가 변경되는 도중에도 스키마 변경을 할 수 있도록 "Online DDL"이라는 기능을 제공한다. 하지만 몬든 스키마 변경이 온라인으로 가능한 것은 아니며, 변경 작업의 특성에 따라 SELECT는 가능하지만 INSERT나 UPDATE 같은 데이터 변경은 허용되지 않을 수도 있다. VARCHAR 데이터 타입을 사용하는 컬럼의 길이를 늘리는 작업은 길이에 따라 매우 빠르게 처리될 수도 있지만 어떤 경우에는 테이블에 대해 읽기 잠금을 걸고 레코드를 복사하는 작업이 필요할 수도 있다.
다음과 같이 길이가 60으로 정의된 VARCHAR 타입의 컬럼을 가진 테이블에서 확장하는 길이에 따른 ALTER TABLE 명령의 결과를 살펴보자.
CREATE TABLE test ( id INT PRIMARY KEY, value VARCHAR(60) ) DEFAULT CHARSET=utf8mb4;value 컬럼의 길이를 63으로 늘리는 경우와 64로 늘리는 경우 Online DDL 명령의 결과는 다음과 같다.

63으로 늘리는 경우 
64로 늘리는 경우 컬럼의 타입을 VARCHAR(63)으로 늘리는 경우는 잠금 없이(LOCK=NONE) 매우 빠르게 변경된 것을 확인할 수 있다. 하지만 컬럼의 타입을 VARCHAR(64)로 늘리는 경우는 INPLACE 알고리즘으로 스키마 변경이 허용되지 않는다는 것을 알 수 있다. 그래서 VARCHAR(64)로 변경하는 경우에는 다음과 같이 COPY 알고리즘으로 스키마 변경을 실행했으며, 스키마 변경 시간도 상당히 많이 걸리게 된다. 그뿐만 아니라 INPLACE 스키마 변경은 잠금 없이 실행되지만 COPY 알고리즘의 스키마 변경은 읽기 잠금(LOCK=SHARED)까지 필요로 한다. 즉 스키마 변경을 하는 동안 test 테이블에는 INSERT나 UPDATE, DELETE를 실행할 수 없게 된다.

rows가 없어서 빠르게 수행됐지만 실제 서비스라면 꽤 큰 차이가 날 것 이러한 차이가 발생하는 이유는 VARCHAR 타입의 컬럼이 가지는 길이 저장 공간의 크기 때문이다. VARCHAR(60)은 utfmb4 문자 집합을 사용하는 VARCHAR(60) 컬럼은 최대 길이가 240(60 * 4)바이트이기 때문에 문자열 값의 길이를 저장하는 공간은 1바이트면 된다. 하지만 VARCHAR(64) 타입은 저장할 수 있는 문자열의 크기가 최대 256바이트까지 가능하기 때문에 문자열 길이를 저장하는 공간의 크기가 2바이트로 바뀌어야 한다. 이처럼 문자열 길이를 저장하는 공간의 크기가 바뀌게 되면 MySQL 서버는 스키마 변경을 하는 동안 읽기 잠금(LOCK=SHARED)을 걸어서 아무도 데이터를 변경하지 못하도록 막고 테이블의 레코드를 복사하는 방식으로 처리한다.
이러한 이유로 문자열 타입의 컬럼을 설계할 때는 앞으로 요건이 바뀌어서 VARCHAR 타입의 길이가 크게 변경될 것으로 예상된다면 길이 저장 공간의 크기가 바뀌지 않도록 미리 조금 크게 설계하는 것이 좋다. 레코드 건수가 많은 테이블에서 읽기 잠금을 필요로 하는 스키마 변경을 실행하기 위해서는 스키마를 변경할 떄마다 서비스를 점검 모드로 바꿔야 할 수도 있으며, 이는 서비스의 가용성을 훼손하게 된다.
콜레이션
문자 집합은 2개 이상의 콜레이션을 가지고 있는데, 하나의 문자 집합에 속한 콜레이션은 다른 문자 집합과 공유해서 사용할 수 없다. 또한 테이블이나 컬럼에 문자 집합만 지정하면 해당 문자 집합의 디폴트 콜레이션이 해당 컬럼의 콜레이션으로 지정된다. 반대로 컬럼의 문자 집합은 지정하지 않고 콜레이션만 지정하면 해당 콜레이션이 소속된 문자 집합이 묵시적으로 그 컬럼의 문자 집합으로 사용된다. MySQL 서버에서 사용 가능한 콜레이션의 목록은 "SHOW COLLATION" 명령을 이용해 다음과 같이 확인할 수 있다.
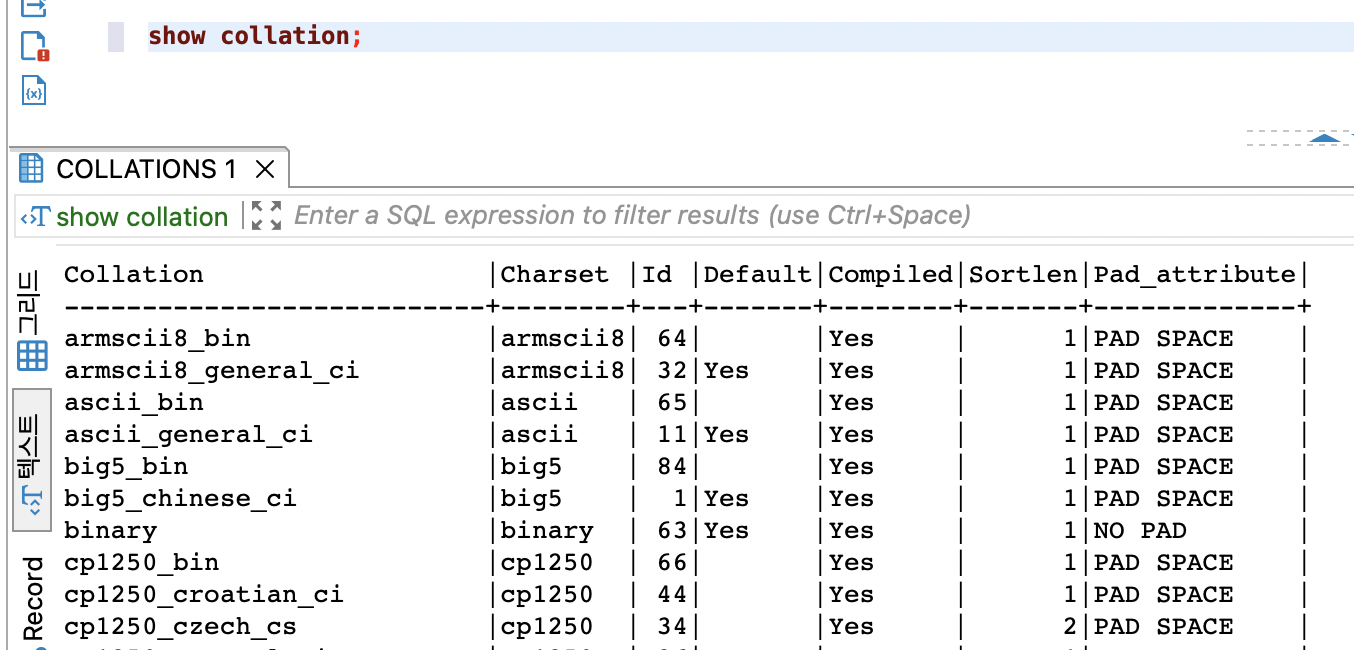
MySQL에서 사용 가능한 콜레이션 목록 일반적으로 콜레이션의 이름은 2개 또는 3개의 파트로 구분돼 있으며, 각 파트는 다음과 같은 의미로 사용된다.
- 3개의 파트로 구성된 콜레이션 이름
- 첫 번째 파트는 문자 집합의 이름이다.
- 두 번째 파트는 해당 문자 집합의 하위 분류를 나타낸.
- 세 번째 파트는 대문자나 소문자의 구분 여부를 나타낸다. 즉, 세 번째 파트가 "ci"이면 대소문자를 구분하지 않는 콜레이션(Case Insensitive)을 의미하며, "cs"이면 대소문자를 별도의 문자로 구분하는 콜레이션(Case Sensitive)이다.
- 2개의 파트로 구성된 콜레이션 이름
- 첫 번째 파트는 마찬가지로 문자 집합의 이름이다.
- 두 번째 파트는 항상 "bin"이라는 키워드가 사용된다. 여기서 "bin"은 이진 데이터(binary)를 의미하며, 이진 데이터로 관리되는 문자열 컬럼은 별도의 콜레이션을 가지지 않는다. 콜레이션이 "xxx_bin"이라면 비교 및 정렬은 실제 문자 데이터의 바이트 값을 기준으로 수행된다.
대부분 문자 집합의 콜레이션 이름은 2~3개의 파트로 구분돼 있었는데, utf8mb4 문자 집합의 콜레이션은 이름이 더 많이 복잡해졌다. utf8mb4 문자 집합의 콜레이션 중에서 "utf8mb4_0900"으로 시작하는 콜레이션에서 "0900"는 UCA(Unicode Collation Algorithm)의 버전을 의미한다. UCA는 문자 비교 규칙 정도로 이해하면 된다.
utf8mb4 문자 집합에서는 액센트 문자의 구분 여부가 콜레이션의 이름에 포함됐다. 예를 들어, "utf8mb4_0900_ai_ci"와 같이 "ai" 또는 "as"를 포함하는 경우가 있는데, 이는 액센트를 가진 문자(Accent Sensitive)와 그렇지 않은 문자(Accent Insensitive)들을 정렬 순서상 동일 문자로 판단할지 여부를 나타낸다. "ai"라면 다음의 5개 문자는 정렬 순서상 동일하게 취급된다. 여기서 한 가지 주의할 것은 콜레이션이 정렬 순서에만 영향을 미치는 것이 아니라 동일 문자인지 아닌지의 검색 겨로가에도 영향을 미친다는 점이다. 정렬의 크다 작다는 개념 자체가 비교의 결과이기 때문이다.
e, è, é, ê, ë콜레이션이 대소문자나 액센트 문자를 구분하지 않는다고 해서 실제 컬럼에 저장되는 값이 모두 소문자나 대문자로 변환되어 저장되는 것은 아니며, 콜레이션과 관계없이 입력된 데이터의 대소문자는 별도의 변환 없이 그대로 저장된다.
MySQL 서버에서 문자열의 정렬이나 검색을 위한 비교 작업이 단순히 저장된 문자열 값의 인코딩된 바이트 값(이를 Code Point라고 한다)으로 비교한다고 생각하는 사용자가 많은데, 이는 사실이 아니다. MySQL 서버는 인코딩된 상태로 저장된 문자열을 가져와 각 인코딩된 바이트 값에 해당하는 콜레이션 값으로 매칭시킨 다음 비교를 수행하게 된다. 즉, 저장된 문자열의 바이트 값은 직접적인 비교 대상이 아니다.자주 사용하는 latin1이나 euckr, utf8mb4 문자 집합의 디폴트 콜레이션은 각각 latin1_swedish_ci, euckr_korean_ci, utf8mb4_0900_ci다. 이들은 모두 대소문자를 구분하지 않는 콜레이션이라서 대소문자를 구분해서 비교하거나 정렬해야 하는 컬럼에서는 "_cs" 계열의 콜레이션을 명시적으로 지정해야 한다. 하지만 utf8mb4 문자 집합이나 euckr과 같이 별도로 "_cs" 계열의 콜레이션을 가지지 않는 문자 집합도 있는데, 이때는 utf8mb4_bin 또는 euckr_bin과 같이 "_bin" 계열의 콜레이션을 사용하면 된다. 일반적으로 각 국가의 언어는 그 나라 국민에게 익숙한 순서대로 문자 코드 값이 부여돼 있으므로 대소문자를 구분할 때는 "_bin" 계열의 콜레이션을 적용해도 특별히 문제되지는 않는다.
MySQL의 문자열 컬럼은 콜레이션 없이 문자 집합만 가질 수는 없다. 콜레이션을 명시적으로 지정하지 않았다면 지정된 문자 집합의 기본 콜레이션이 묵시적으로 적용된다. 그리고 문자열 컬럼의 정렬이나 비교는 항상 해당 문자열 컬럼의 콜레이션에 의해 판단하므로 문자열 컬럼에서는 CHAR나 VARCHAR 같은 타입의 이름과 길이만 같다고 해서 똑같은 타입이라고 판단해서는 안 된다. 타입의 이름과 문자열의 길이, 문자 집합과 콜레이션까지 일치해야 똑같은 타입이라고 할 수 있다. 문자열 컬럼에서는 문자 집합과 콜레이션이 모두 일치해야 조인이나 WHERE 조건이 인덱스를 효율적으로 사용할 수 있다. 조인을 수행하는 양쪽 테이블의 컬럼이 문자 집합이나 콜레이션이 다르다면 비교 작업에서 콜레이션의 변환이 필요하기 때문에 인덱스를 효율적으로 이용하지 못할 때가 많으므로 주의해야 한다.
대표적으로 latin 계열의 문자 집합에 대해 _ci, _cs, _bin 콜레이션의 정렬 규칙을 테스트해 보기 위해 tb_collate 테이블에 여러 종류의 콜레이션을 섞어서 테이블을 생성해봤다. 컬럼명은 이해를 위해 콜레이션의 이름을 포함해서 생성했다.
CREATE TABLE tb_collate ( fd_latin1_general_ci VARCHAR(10) COLLATE latin1_general_ci, fd_latin1_general_cs VARCHAR(10) COLLATE latin1_general_cs, fd_latin1_bin VARCHAR(10) COLLATE latin1_bin, fd_latin7_general_ci VARCHAR(10) COLLATE latin7_general_ci ); INSERT INTO tb_collate VALUES ('a','a','a','a'), ('A','A','A','A'), ('b','b','b','b'), ('B','B','B','B'), ('_','_','_','_'), ('-','-','-','-'), ('.','.','.','.'), ('~','~','~','~');
latin1_general_ci로 정렬한 결과 
latin1_general_cs로 정렬한 결과 
latin1_bin로 정렬한 결과 
latin7_general_ci로 정렬한 결과 위의 예제 쿼리에서 각 정렬이 어떻게 수행됐고 각 콜레이션에서 주의할 사항으로 어떤 것이 있는지 살펴보자.
- 첫 번째 에제는 latin1_general_ci 콜레이션을 사용하는 컬럼을 기준으로 정렬했다. 출력된 정렬 순서로 보면 'a'와 'A' 중에서 소문자가 먼저인 것처럼 보이지만 사실 대소문자 구분 없이 정렬된 것이다.
- 두 번째 예제는 latin1_general_cs 콜레이션으로 정렬한 것인데, 대문자 'A'와 소문자 'a'는 모두 대문자 'B'보다 먼저 정렬됐다. 그런데 같은 알파벳에서는 대문자가 소문자보다 먼저 정렬됐다.
- 세 번째 예제는 latin1_bin 콜레이션으로 정렬한 에제로 대문자만 먼저 정렬되고 그다음으로 소문자가 정렬됐다.
- 네 번째 예제는 조금 다른 성격의 정렬인데, 첫 번째부터 세 번째 정렬은 모두 특수 문자의 정렬 위치가 알파벳의 앞뒤로 분산돼 있다. 그런데 특수문자만 먼저 정렬하고 알파벳을 그다음으로 정렬하기 원할 수도 있다. 이때는 latin1이 아니라 latin7 문자셋을 사용하면 특수문자가 알파벳보다 먼저 정렬된다.
때로는 WHERE 조건의 검색은 대소문자를 구분하지 않고 실행하되 정렬은 대소문자를 구분해서 해야 할 때도 있는데, 이때는 검색과 정렬 작업 중 하나는 인덱스를 이용하는 것을 포기할 수밖에 없다. 주로 이 때는 컬럼의 콜레이션을 "_ci"로 만들어 검색은 인덱스를 충분히 이용할 수 있게 하고, 정렬 작업은 인덱스를 사용하지 않는 명시적인 정렬(Using filesort) 형태로 처리하는 것이 일반적이다. 검색과 정렬 모두 인덱스를 이용하려면 정렬을 위한 콜레이션을 사용하는 컬럼을 하나 더 추가하고 검색은 원본 컬럼을, 그리고 정렬은 복사된 추출 컬럼을 이용하는 방법도 생각해볼 수 있다. 데이터의 양이나 업무의 중요도를 적절히 반영해 방법을 선택하면 될 것이다.
비교 방식
MySQL에서 문자열 컬럼을 비교하는 방식은 CHAR와 VARCHAR가 거의 같다. CHAR 타입의 컬럼에 SELECT를 실행했을 때 다른 DBMS처럼 사용되지 않은 공간에 공백 문자가 채워져서 나오지 않는다. 그리고 MySQL 서버에서 지원하는 대부분의 문자 집합과 콜레이션에서 CHAR 타입이나 VARCHAR 타입을 비교할 때 공백 문자를 뒤에 붙여서 두 문자열의 길이를 동일하게 만든 후 비교를 수행한다. 다음의 간단한 예제를 보면 더 쉽게 이해할 수 있을 것이다.
SELECT 'ABC'='ABC ' is_equal; +--------+ |is_equal| +--------+ | 1| +--------+ SELECT 'ABC'=' ABC' is_equal; +--------+ |is_equal| +--------+ | 0| +--------+첫 번째 예제 쿼리의 결과를 보면 "ABC"라는 문자열 뒤에 붙어 있는 3개의 공백은 있어도 없는 것처럼 비교했다는 것을 알 수 있다. 그리고 두 번째 쿼리의 결과를 보면 "ABC"라는 문자열의 앞쪽에 위치하는 공백 문자는 유효한 문자로 비교된다는 사실을 알 수 있다. 이러한 문자열 비교 방식은 문자열의 크다(>) 작다(<) 비교와 문자열을 비교 함수인 STRCMP()에서도 똑같이 적용된다.
하지만 utf8mb4 문자 집합이 UCA 버전 9.0.0을 지원하면서 문자열 뒤에 붙어있는 공백 문자들에 대한 비교 방식이 달라졌다. 다음 예제 쿼리를 보면 utf8mb4_bin 콜레이션을 사용하는 경우 문자열 뒹 ㅔ붙어 있는 공백은 비교에 영향을 미치지 않는다. 하지만 utf8mb4_0900_bin 콜레이션을 사용하는 경우 문자열 뒤의 공백이 비교 결과에 영향을 미치는 것을 알 수 있다.
SET NAMES utf8mb4 COLLATE utf8mb4_bin SELECT 'a '='a' is_equal; +--------+ |is_equal| +--------+ | 1| +--------+ SET NAMES utf8mb4 COLLATE utf8mb4_0900_bin SELECT 'a '='a' is_equal; +--------+ |is_equal| +--------+ | 0| +--------+이는 지금까지 MySQL 서버의 문자열 비교 규칙에 큰 영향을 미치는 변경이므로 utf8mb4 문자 집합을 사용하는 경우 주의해야 한다. 문자열 뒤의 공백이 비교 결과에 영향을 미치는지 아닌지는 다음과 같이 information_schema 데이터베이스의 COLLATIONS 뷰에서 PAD_ATTRIBUTE 컬럼의 값으로 판단할 수 있다.
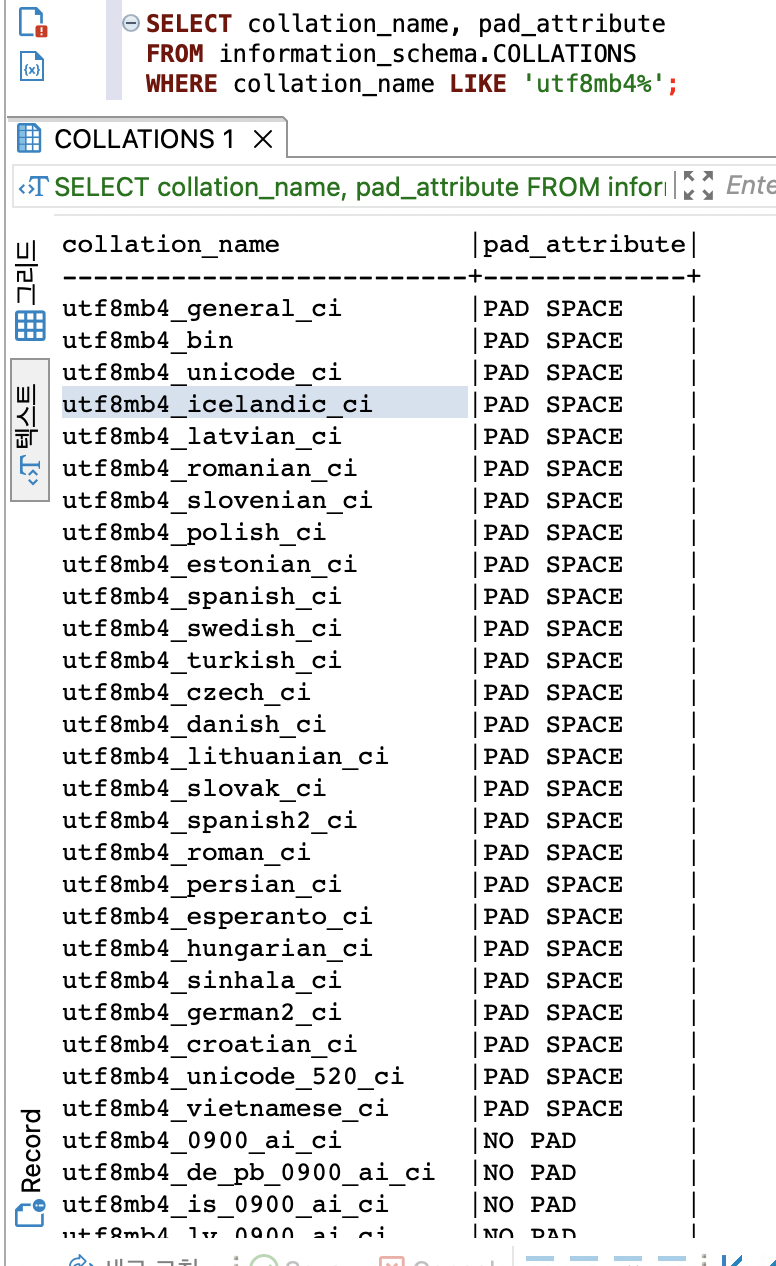
pad_attribute 확인 pad_attribute 컬럼의 값이 "PAD SPACE"라고 표시된 콜레이션에서는 비교 대상 문자열의 길이가 같아지도록 문자열 뒤에 공백을 추가해서 비교를 수행한다. 그리고 "NO PAD"로 표시된 콜레이션에서는 별도로 문자열의 길이를 일치시키지 않고 그대로 비교한다. MySQL 서버에서 지원하는 대부분의 콜레이션은 "PAD SPACE"이며, "utf8mb4_0900"으로 시작하는 콜레이션만 "NO PAD"다. 이 같은 이유로 "utf8mb4_0900"으로 시작하는 콜레이션은 비교 대상 문자열의 길이가 많이 차이 나는 경우 더 빠른 비교 성능을 낸다.
문자열 비교의 경우 예외적으로 LIKE를 사용한 문자열 패턴 비교에서는 공백 문자가 유효 문자로 취급된다. LIKE 조건으로 비교하는 예제를 한 번 살펴보자.
SELECT 'ABC ' LIKE 'ABC' AS is_same_pattern; +---------------+ |is_same_pattern| +---------------+ | 0| +---------------+ SELECT ' ABC' LIKE 'ABC' AS is_same_pattern; +---------------+ |is_same_pattern| +---------------+ | 0| +---------------+ SELECT 'ABC ' LIKE 'ABC%' AS is_same_pattern; +---------------+ |is_same_pattern| +---------------+ | 1| +---------------+위의 비교 예제를 보면 첫 번쨰와 두 번째 쿼리에서 문자열의 앞뒤에 있는 공백이 모두 유효한 문자 값으로 인식됐음을 알 수 있다. 그리고 실제 이런 값을 비교하려면 세 번째 쿼리와 같이 검색어 앞뒤로 와일드 카드("%") 문자를 사용해야 한다는 것을 알 수 있다. MySQL의 독특한 문자열 비교 방식은 주로 회원의 아이디나 닉네임과 같이 다른 DBMS와 연동해야 하는 서비스에서 문제가 되곤 하므로 주의해야 한다.
숫자
숫자를 저장하는 타입은 값의 정확도에 따라 크게 참값(Exact value)과 근삿값 타입으로 나눌 수 있다.
- 참값은 소수점 이하 값의 유무와 관계없이 정확히 그 값을 그대로 유지하는 것을 의미한다. 참값을 관리하는 데이터 타입으로는 INTEGER를 포함해 INT로 끝나는 타입과 DECIMAL이다.
- 근삿값은 흔히 부동 소수점이라고 불리는 값을 의미하며, 처음 컬럼에 저장한 값과 조회된 값이 정확하게 일치하지 않고 최대한 비슷한 값으로 관리하는 것을 의미한다. 근삿값을 관리하는 타입으로는 FLOAT과 DOUBLE이 있다.
또한 값이 저장되는 포맷에 따라 십진 표기법(DECIMAL)과 이진 표기법으로 나눌 수 있다.
- 이진 표기법이란 흔히 프로그래밍 언어에서 사용하는 정수나 실수 타입을 의미한다. 이진 표기법은 한 바이트로 한 자리 또는 두 자리 숫자만 저장하는 것이 아니라 256까지의 숫자(양수만 저장한다고 가정할 경우)를 표현할 수 있기 때문에 숫자 값을 적은 메모리나 디스크 공간에 저장할 수 있다. MySQL의 INTEGER나 BIGINT 등 대부분 숫자 타입은 모두 이진 표기법을 사용한다.
- 십진 표기법(DECIMAL)은 숫자 값의 각 자릿값을 표현하기 위해 4비트나 한 바이트를 사용해서 표기하는 방법이다. 이는 우리가 흔히 이야기하는 십진수가 아니라 디스크나 메모리에 십진 표기법으로 저장된다는 것을 의미한다. MySQL의 십진 표기법을 사용하는 타입은 DECIMAL 뿐이며, DECIMAL 타입은 금액(돈)처럼 정확하게 소수점까지 관리돼야 하는 값을 저장할 때 사용한다. 또한 DECIMAL 타입은 65자리 숫자까지 표현할 수 있으므로 BIGINT로도 저장할 수 없는 값을 저장할 때 사용한다.
DBMS에서는 근삿값은 저장할 때와 조회할 때의 값이 정확히 일치하지 않고, 유효 자릿수를 넘어서는 소수점 이하의 값은 계속 바뀔 수 있다. 특히 STATEMENT 포맷을 사용하는 복제에서는 소스 서버와 레플리카 서버 간 데이터 차이가 발생할 수도 있다. MySQL에서 FLOAT이나 DOUBLE과 같은 부동 소수점 타입은 잘 사용하지 않는다. 또한 십진 표기법을 사용하는 DECIMAL 타입은 이진 표기법을 사용하는 타입보다 저장 공간을 2배 이상 필요로 한다. 매우 큰 숫자 값이나 고정 소수점을 저장해야 하는 것이 아니라면 일반적으로 INTEGER나 BIGINT 타입을 자주 사용한다.
정수
DECIMAL 타입을 제외하고 정수를 저장하는 데 사용할 수 있는 데이터 타입으로는 5가지가 있다. 이것들은 저장 가능한 숫자 값의 범위만 다를 뿐 다른 차이는 거의 없다. 정수 값을 위한 타입은 아주 직관적이다. 입력이 가능한 수의 범위 내에서 최대한 저장 공간을 적게 사용하는 타입을 선택하면 된다.
데이터 타입 저장공간
(Bytes)최솟값
(Signed)최솟값
(Unsigned)최댓값
(Signed)최댓값
(Unsigned)TINYINT 1 -128 0 127 255 SMALLINT 2 -32768 0 32767 65535 MEDIUMINT 3 -8388608 0 8388607 16777215 INT 4 -2147483648 0 2147483647 4294967295 BIGINT 8 -263 0 263-1 264-1 정수 타입은 UNSIGNED라는 컬럼 옵션을 사용할 수 있다. 정수 컬럼을 생성할 때 UNSIGNED 옵션을 명시하지 않으면 기본적으로 음소와 양수를 동시에 저장할 수 있는 숫자 타입(SIGNED)이 된다. 하지만 UNSIGNED 옵션이 설정된 정수 컬럼에서는 0보다 큰 양의 정수만 저장할 수 있게 되면서 저장할 수 있는 최댓값은 SIGNED 타입보다 2배가 더 커진다. AUTO_INCREMENT 컬럼과 같이 음수가 될 수 없는 값을 저장하는 컬럼에 UNSIGNED 옵션을 명시하면 작은 데이터 공간으로 더 큰 값을 저장할 수 있다.
물론 정수 타입에서 UNSIGNED 옵션은 조인할 때 인덱스의 사용 여부까지 영향을 미치지는 않는다. 즉 UNSIGNED 정수 컬럼과 SIGEND 정수 컬럼은 조인할 때 인덱스를 이용하지 못한다거나 하는 문제는 발생하지 않는다. 하지만 서로 저장되는 값의 범위가 다르므로 외래 키로 사용하는 컬럼이나 조인의 조건이 되는 컬럼은 SIGNED나 UNSIGNED 옵션을 일치시키는 것이 좋다.
부동 소수점
MySQL에서는 부동 소수점을 저장하기 위해 FLOAT와 DOUBLE 타입을 사용할 수 있다. 부동 소수점이라는 이름에서 부동(浮動, Floating point)은 소수점의 위치가 고정적이지 않다는 의미인데, 숫자 값의 길이에 따라 유효 범위의 소수점 자릿수가 바뀐다. 그래서 부동 소수점을 사용하면 정확한 유효 소수점 값을 식별하기 어렵고 그 값을 따져서 크다 작다를 비교를 하기가 쉽지 않은 편이다. 부동 소수점은 근삿값을 저장하는 방식이라서 동등 비(Equal)는 사용할 수 없다. 이 밖에도 MySQL 매뉴얼을 살펴보면 부동 소수점을 사용할 때 주의할 내용이 많이 있으므로 사용하기 전에 반드시 참조할 것을 권장한.
복제에 참여하는 MySQL 서버에서 부동 소수점을 사용할 때는 특별히 주의해야 한다. 부동 소수점 타입의 데이터는 MySQL 서버의 바이너리 로그 포맷이 STATEMENT 타입인 경우 복제에서 소스 서버와 레플리카 서버 간의 데이터가 달라질 수 있다. 물론 유효 정수부나 소수부는 달라지지 않겠지만 앞에서도 언급했듯이 유효 정수부나 소수부를 눈으로 판별하기는 쉽지 않다.
DECIMAL
부동 소수점에서 유효 범위 이외의 값은 가변적이므로 정확한 값을 보장할 수 없다. 즉, 금액이나 대출 이자 등과 같이 고정된 소수점까지 정확하게 관리해야 할 때는 FLOAT이나 DOUBLE 타입을 사용해서는 안 된다. 그래서 소수점의 위치가 가변적이지 않은 고정 소수점 타입을 위해 DECIMAL 타입을 제공한다.
MySQL에서 소수점 이하의 값까지 정확하게 관리하려면 DECIMAL 타입을 이용해야 한다. DECIMAL 타입은 숫자 하나를 저장하는 데 1/2바이트가 필요하므로 한 자리나 두 자릿수를 저장하는 데 1바이트가 필요하고 세 자리나 네 자리 숫자를 저장하는 데는 2바이트가 필요하다. 즉, DECIMAL로 저장하는 (숫자의 자릿수)/2의 결괏값을 올림 처리한 만큼의 바이트 수가 필요하다. 그리고 DECIMAL 타입과 BIGINT 타입의 값을 곱하는 연산을 간단히 테스트해 보면 아주 미세한 차이지만 DECIMAL보다는 BIGINT 타입이 더 빠르다는 사실을 알 수 있다. 결론적으로 소수가 아닌 정숫값을 관리하기 위해 DECIMAL 타입을 사용하는 것은 성능상으로나 공간 사용면에서 좋지 않다. 단순히 정수를 관리하고자 한다면 INTEGER나 BIGINT를 사용하는 것이 좋다.
정수 타입의 컬럼을 생성할 때의 주의사항
부동 소수점이나 DECIMAL 타입을 이용해 컬럼을 정의할 때는 타입의 이름 뒤에 괄호로 정밀도를 표시하는 것이 일반적이다. 예를 들어, DECIMAL(20, 5)라고 정의하면 정수부를 15(=20-5)자리까지, 그리고 소수부를 5자리까지 저장할 수 있는 DECIMAL 타입을 생성한다. 그리고 DECIMAL(20)이라고 정의하는 경우에는 소수부 없이 정수부반 20자리까지 저장할 수 있는 타입의 컬럼을 생성한다. FLOAT나 DOUBLE 타입은 저장 공간의 크기가 고정이므로 정밀도를 조절한다고 해서 저장 공간의 크기가 바뀌는 것은 아니다. 하지만 DECIMAL 타입은 저장 공간의 크기가 가변적인 데이터 타입이어서 DECIMAL 타입에 사용하는 정밀도는 저장 가능한 자릿수를 결정함과 동시에 저장 공간의 크기까지 제한한다.
TEXT와 BLOB
MySQL에서 대량의 데이터를 저장하려면 TEXT나 BLOB 타입을 사용해야 하는데, 이 두 타입은 많은 부분에서 거의 똑같은 설정이나 방식으로 작동한다. TEXT 타입과 BLOB 타입의 유일한 차이점은 TEXT 타입은 문자열을 저장하는 대용량 컬럼이라서 문자 집합이나 콜레이션을 가진다는 것이고, BLOB 타입은 이진 데이터 타입이라서 별도의 문자 집합이나 콜레이션을 가지지 않는다는 것이다. 다음 표와 같이 TEXT와 BLOB 타입 모두 다시 내부적으로 저장 가능한 최대 길이에 따라 4가지 타입으로 구분한다.
데이터 타입 필요 저장 공간
(L = 저장하고자 하는 데이터의 바이트 수)저장 가능한 최대 바이트 수 TINYTEXT, TINYBLOB L + 1바이트 255 TEXT, BLOB L + 2바이트 65,535 MEDIUMTEXT, MEDIUMBLOB L + 3바이트 16,777,215 LONGTEXT, LONGBLOB L + 4바이트 4,294,967,295 LONG이나 LONG VARCHAR라는 타입도 있는데, MEDIUMTEXT의 동의어이므로 특별히 기억할 필요는 없다. 이진 데이터를 저장하기 위한 데이터 타입과 문자열을 저장하기 위한 데이터 타입은 다음과 같이 고정 길이나 가변 길이 타입이 정확하게 매핑된다.
고정길이 가변길이 대용량 문자 데이터 CHAR VARCHAR TEXT 이진 데이터 BINARY VARBINARY BLOB 오라클 DBMS의 영향인지 많은 사람이 BLOB 타입에 대해서는 대용량 컬럼이라는 인식을 가지고 주의하는 데 반해, TEXT 타입은 그다지 부담을 가지지 않고 사용하는 경향도 있다. MySQL의 TEXT 타입은 오라클에서 CLOB라고 하는 대용량 타입과 동일한 역할을 하는 데이터 타입이므로 TEXT와 BLOB 컬럼 모두 사용할 때 주의하고 너무 남용해서는 안된다. TEXT나 BLOB 타입은 주로 다음과 같은 상황에서 사용하는 것이 좋다.
- 컬럼 하나에 저장되는 문자열이나 이진 값의 길이가 예측할 수 없이 클 때 TEXT나 BLOB을 사용한다. 하지만 다른 DBMS와는 달리 MySQL에서는 값의 크기가 4000바이트를 넘을 때 반드시 BLOB나 TEXT를 사용해야 하는 것은 아니다. MySQL에서는 레코드의 전체 크기가 64KB를 넘지 않는 한도 내에서는 VARCHAR나 VARBINARY의 길이는 제한이 없다. 그래서 용도에 따라서는 다음 예제와 같이 4000바이트 이상의 값을 저장하는 컬럼도 VARCHAR나 VARBINARY 타입을 이용할 수 있다.
- MySQL에서는 버전에 따라 조금씩 차이는 있지만 일반적으로 하나의 레코드는 전체 크기가 64KB를 넘어설 수 없다. VARCHAR나 VARBINARY와 같은 가변 길이 컬럼은 최대 저장 가능 크기를 포함해 64KB로 크기가 제한된다. 레코드의 전체 크기가 64KB를 넘어서서 더 큰 컬럼을 추가할 수 없다면 일부 컬럼을 TEXT나 BLOB 타입으로 전환해야 할 수도 있다.
CREATE TABLE tb_varchar ( id INT NOT NULL, body VARCHAR(6000), PRIMARY KEY(id) );'책책책 책을 읽읍시다 > 프로그래밍' 카테고리의 다른 글
카프카 핵심 가이드 1 - 카프카 입문 (0) 2023.06.06 Redis 운영 관리 (0) 2023.05.06 Real MySQL 8.0 5 - 파티션 (0) 2023.05.03 Real MySQL 8.0 4 - 쿼리 작성 및 최적화 (0) 2023.05.01 Real MySQL 8.0 3 : 옵티마이저와 힌트 그리고 실행계획 (0) 2023.04.29